PyTorch是基于torch的Python开源机器学习库,主要提供以下两种服务:
- 作为NumPy的替代品,使用GPU的强大计算力(通过张量实现)
- 提供最大的灵活性和高速的深度学习研究平台(包含自动求导系统的深度神经网络)
本文主要记录PyTorch的基本运算单元Tensor及其相关的操作。
张量(Tensor)是PyTorch里面基础的运算单元,与NumPy的ndarry相同,都表示的是一个数据类型相同的多维矩阵。与ndarry的最大区别就是,Tensor可以在GPU上运行,ndarry只能在CPU上运行。张量本质上是一个矩阵,就存在着创建、索引、算数操作、逻辑操作以及维度操作等方法以及数据类型等属性。
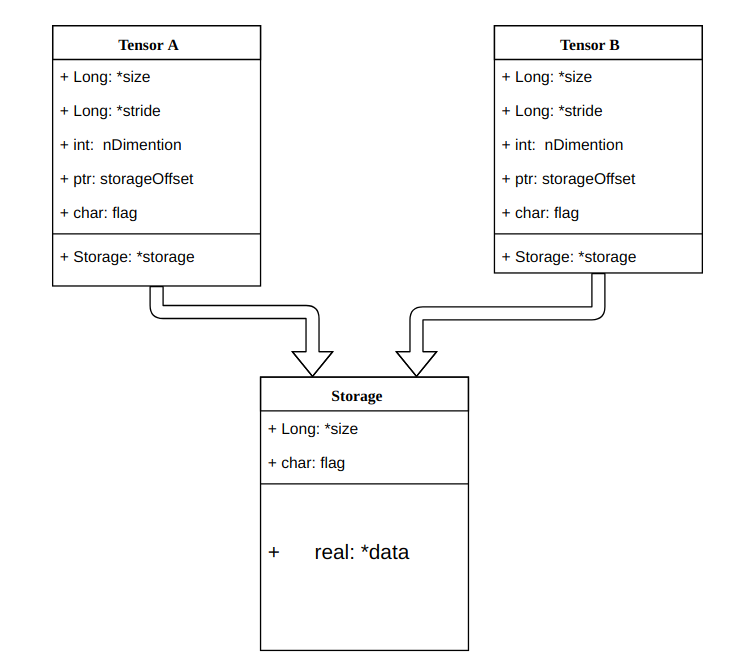
1. Tensor的数据结构
- 信息区:形状,步长,数据类型等
- 存储区(Storage):用一个连续数组存储真正的数据,通过size, stride,offset进行元素访问。
1.1 Tensor的数据类型
Tensor的基本数据类型有八种:
- 16位浮点型(Half)
- 32位浮点型(Float)
- 64位浮点型(Double)
- 8位无符号整型(Byte)
- 8位有符号整型(Char)
- 16位整型(Short)
- 32位整型(Int)
- 64位整型(Long)
默认类型为torch.FloatTensor。
1.2 Tensor的属性
torch.dtype:标识了张量的数据类型torch.device:标识了张量创建以后所存储的设备的名称。torch.device包含了两种设备类型(‘cpu’或’gpu’),分别标识将Tensor对象存储于CPU或者GPU中,同时指定设备号,比如多张GPU,可以通过’cuda:X’来指定编号为X的GPU。1
2
3torch.device('cpu')
torch.device('gpu')
torch.device('gpu:1')torch.layout:标识了张量在内存中的布局模式。目前支持两种内存布局模式torch.strided(dense Tensors)和torch.sparse_coo(稀疏矩阵存储方式)
2. 创建Tensor
2.1 从已经存在的数据生成Tensor
1 | torch.tensor(data,dtype=None,device=None,requires_grad=False) |
2.2 创建特殊类型的Tensor
创建指定数值的Tensor
1 | torch.ones(*sizes,out=None) # 返回全1的Tensor,其形状有可变参数sizes定义 |
创建指定矩阵类型的Tensor
1 | torch.eye(n,m=None,out=None) # 返回对角线位置为1,其他位置为0的二维张量,参数`m`默认等于`n` |
创建随机数类型的Tensor
1 | # 均匀分布 |
3. 操作Tensor
从接口的角度讲,对Tensor的操作分为两类:
torch.functiontensor.function
从存储的角度讲,对Tensor的操作又可分为两类:
- 不会修改自身数据的操作,如
add() - 会修改自身数据的操作,如
add_()
3.1 基本操作
索引
Tensor支持与Numpy类似的索引操作,其语法上也类似,通过索引可以对Tensor中的数据进行修改。1
2
3
4a = torch.randn(3,4)
a[:] # 索引全部元素
a[:2] # 索引前两行的元素,索引左闭右开
a[0:2,1] # 索引前两行第二列的元素除了索引操作符外,还有一些其他常用的选择函数。
1
2
3
4torch.take(input,index) # 输入张量被看作一维张量,返回给定索引位置元素组成的张量
torch.index_select(input,dim,index,out=None) # 返回在指定维度dim上索引为index张量,index必须是一个张量
torch.masked_select(input,mask,out=None) # 根据mask来返回一个一维张量
torch.nonzero(input) # 返回非0元素的下标拼接
1
2
3
4
5
6
7torch.cat(seq,dim=0,out=None) # 沿着指定维度dim拼接seq中的张量,张量除被拼接维度外,其他维度必须相同或者张量为empty
torch.stack(seq,dim=0,out=None) # 沿着指定维度堆叠张量,张量形状必须完全一致
a = torch.randn(2,4)
b = torch.randn(3,4)
c = torch.randn(3,4)
torch.cat([a,b],dim=0) # 返回shape为[5,4]的张量
torch.stack([b,c],dim=0) # 返回shape为[2,3,4]的张量
NOTE:cat会增加指定维度的长度,可以理解为续接;stack会增加一个新的维度,可以理解为堆叠。
- 分割
1
2
3
4
5torch.split(input,split_size_or_sections,dim=0) # 在维度dim上将张量按照split_size进行分割,split_size_or_sections表示每一个子张量的大小
torch.chunk(input,chunks,dim=0) # 在维度dim上将张量均匀分割为chunks个子张量
a = torch.randn(5,6)
torch.split(a,[2,3],dim=0) # 在行上进行分割,得到shape为[2,6]和[3,6]的两个张量
torch.chunk(a,2,dim=1) # 在列上进行均匀分割,得到shape为[5,3]的两个张量
NOTE:chunk相当于均匀分割的split,建议只在能被整除的情况下使用。
- 变换
1
2
3
4
5
6
7torch.transpose(input,dim0,dim1,out=None) # 返回input的转置矩阵,交换给定维度dim0和dim1
torch.t(input,out=None) # 返回input的转置矩阵,input是二维张量
torch.squeeze(input,dim=None,out=None) # 移除指定size为1的维度,默认移除全部size为1的维度
torch.unsqueeze(input,dim,out=None) # 在指定方向扩展张量的维度,新维度大小为1,如将[n,m]张量扩展为[n,1,m]张量
torch.reshape(input,shape) # 指定张量的新shape,reshape之后不会改变数据的值和数据格式
torch.unbind(input,dim=0) # 移除张量的一个维度,返回一个元组,包含了沿着指定维度切片后的各个切片
torch.where(condition,x,y) # 逐个位置判断元素是否满足条件condition,满足返回x中对应位置的值或者x的值,不满足返回y在对应位置的值或y的值
NOTE:
reshape和view都可以改变张量的shape,不同在于view要保证张量是contiguous
3.2 数学操作
逐点操作
- 加减乘:
torch.add(input,value,out=None)/torch.div()/torch.mul() - 三角函数:
torch.sin(input,out=None)/torch.cos()/torch.tan() - 指数运算:
torch.exp(input,out=None) - 对数运算:
torch.log(input,out=None)/torch.log2(input,out=None)/torch.log10(input,out=None) - 幂运算:
torch.pow(input,exponent,out=None) - 截断函数:
1
2
3
4
5
6
7
8
9torch.ceil(input,out=None)
torch.floor(input,out=None)
torch.round(input,out=None)
torch.clamp(input, min, max out=None) # input < min,返回min,input > max,返回max
torch.trunc(input,out=None) # 返回整数部分数值
torch.frac(input,out=None) # 返回小数部分数值
torch.ceil(input,divisor,out=None) # 返回input/divisor的余数 - 其他:
1
2
3
4torch.neg(input,out=None) # 取反
torch.reciprocal(input,out=None) # 取倒数
torch.sqrt(input,out=None) # 开方
torch.sigmod(input,out=None) # 激活函数
- 加减乘:
降维
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17torch.argmax(input,dim=None,out=None) # 返回指定维度上最大值的索引
torch.argmax(input,dim=None,out=None) # 返回指定维度上最小值的索引
torch.mean(input, dim, keepdim=False, out=None)
torch.median(input, dim=-1, keepdim=False)
torch.mode(input, dim=-1, keepdim=False, values=None) # 众数
torch.sum(input, dim, keepdim=False, out=None)
torch.prod(input, dim, keepdim=False, out=None) # 乘积
torch.unique(input,sorted=False) # 去除重复值
torch.mean(input, dim, keepdim=False, out=None)
torch.std(input, dim, keepdim=False, unbiased=True, out=None) # unbiased是否使用无偏估计
torch.var(input, dim, keepdim=False, unbiased=True, out=None)
torch.norm(input, p, dim, keepdim=False, out=None) # 返回指定维度的p-范数
torch.dist(input, other, p=2) # 返回(input-other)的p-范数比较运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16torch.eq(input, other, out=None) # 比较元素是否相等
torch.equal(tensor1, tensor2) # 比较是否有相同的size和元素
torch.ge(input, other, out=None) # input>= other
torch.gt(input, other, out=None) # input>other
torch.le(input, other, out=None) # input=<other
torch.lt(input, other, out=None) # input<other
torch.ne(input, other, out=None) # input != other 不等于
torch.max(input, dim, keepdim=False, out=None)
torch.min(input, dim, keepdim=False, out=None)
torch.isnan(input) # 判断是否有NaN
torch.sort(input, dim=None, descending=False, out=None) # 指定维度进行排序
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) # 指定维度的k个最值及其索引,largest确定最大还是最小
torch.kthvalue(input, k, dim=None, keepdim=False, out=None) # 指定维度k个最小值及其索引频谱运算
1
2torch.fft(input, signal_ndim, normalized=False)
torch.ifft(input, signal_ndim, normalized=False)其他运算
1
2
3
4
5
6torch.cross(input, other, dim=-1, out=None) # 两个张量的向量积(叉积)
torch.dot(tensor1, tensor2) # 点积
torch.trace(input) # 对角线元素的和,即迹
torch.eig(a, eigenvectors=False, out=None) # 计算矩阵的特征值和特征向量
torch.mm(mat1, mat2, out=None) # 矩阵乘法
3.3 序列化操作
Pytorch使用
pickle来进行张量的序列化操作,使用方法如下:1
2
3
4
5
6
7torch.save(tensor,'./tensor_file.t')
with open('./tensor_file.t','wb') as f:
torch.save(tensor,f)
torch.load('./tensor_file.t')
with open('./tensor_file.t','rb') as f:
tensor = torch.load(f)也可以通过
h5py进行序列化
3.4 并行操作
1 | torch.get_num_threads() # 获得 OpenMP 并行化操作的线程数目 |